



























随着短视频行业的爆发增长,数字人视频需求激增,但传统制作方式面临唇形不同步、制作周期长、成本高等问题。这些挑战严重影响了内容质量和用户体验。下面看看语鹦学舌如何解决这些问题。
人工智能如何实现1比1唇形同步效果?
语鹦学舌通过多项创新技术实现了精准的唇形同步效果。首先,系统采用高精度唇形捕捉技术,在视频采集阶段详细记录用户说话时的嘴型变化,包括嘴唇开合度、口型变化和下巴动作等微小细节,建立个性化的唇形映射库。

其次,语鹦学舌运用深度学习算法建立音素与唇形之间的精准对应关系。当输入新文字内容时,系统先将文字转换为音素序列,再通过AI模型预测每个音素对应的唇形变化。这一过程考虑了语言发音规律、停顿节奏和情感变化,大大提升了同步效果。
更重要的是,语鹦学舌融合了情境感知技术,让数字人的唇形变化不只是机械跟随声音,而是能根据语句情感和语境做出调整。例如,表达惊讶时会自动调整嘴型的夸张程度,表达思考时会调整唇形变化的速度和幅度,使数字人表现更加生动自然。

系统还特别注重过渡帧处理,生成足够多的中间过渡帧,确保唇形变化连续平滑,消除跳帧现象,这在快速语速和复杂发音时尤为重要,是许多其他技术容易忽视的细节。

制作一条60秒的数字人视频需要多长时间?
与传统制作方式可能需要数天甚至更长时间不同,语鹦学舌将60秒数字人视频的制作时间缩短到了惊人的几分钟。
整个制作流程简单高效。首先是用户初始化训练,上传10-20秒的声音样本和10秒到4分钟的视频样本。语鹦学舌的算法能在几分钟内完成声音和形象训练,不需要等待数小时或数天。
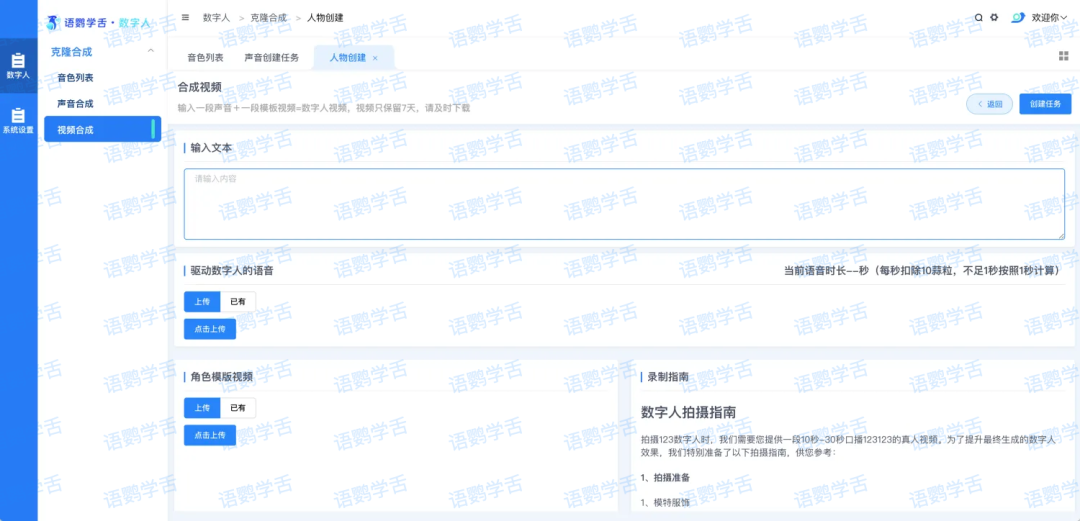
完成初始化后,用户只需输入想要数字人说的文字内容,系统就能自动生成对应视频。对于60秒长度的视频,通常只需几分钟就能完成从文字到成品的全过程。这种近乎实时的生成速度对需要快速响应热点的创作者尤为重要。
值得一提的是,语鹦学舌的高效不以牺牲质量为代价。即使快速生成的视频也能保持出色的唇形同步效果和声音还原度。系统采用并行计算技术同时处理声音合成和视频生成,配合云端高性能GPU集群,确保稳定的处理速度。

相比传统制作流程需要专业摄影基地、灯光设备、模特和耗时的后期处理,语鹦学舌将复杂流程简化为几个简单步骤,让用户足不出户就能完成高质量数字人视频制作。

这种效率革命让各类用户受益:内容创作者能更快更新内容抓住热点;企业可快速制作更新宣传视频;教育工作者能高效生成教学内容。无论什么应用场景,语鹦学舌都能通过高效技术为用户节省宝贵时间和精力,同时保证出色的视频质量。现在语鹦学舌限时开放免费体验,快来试一下吧!

